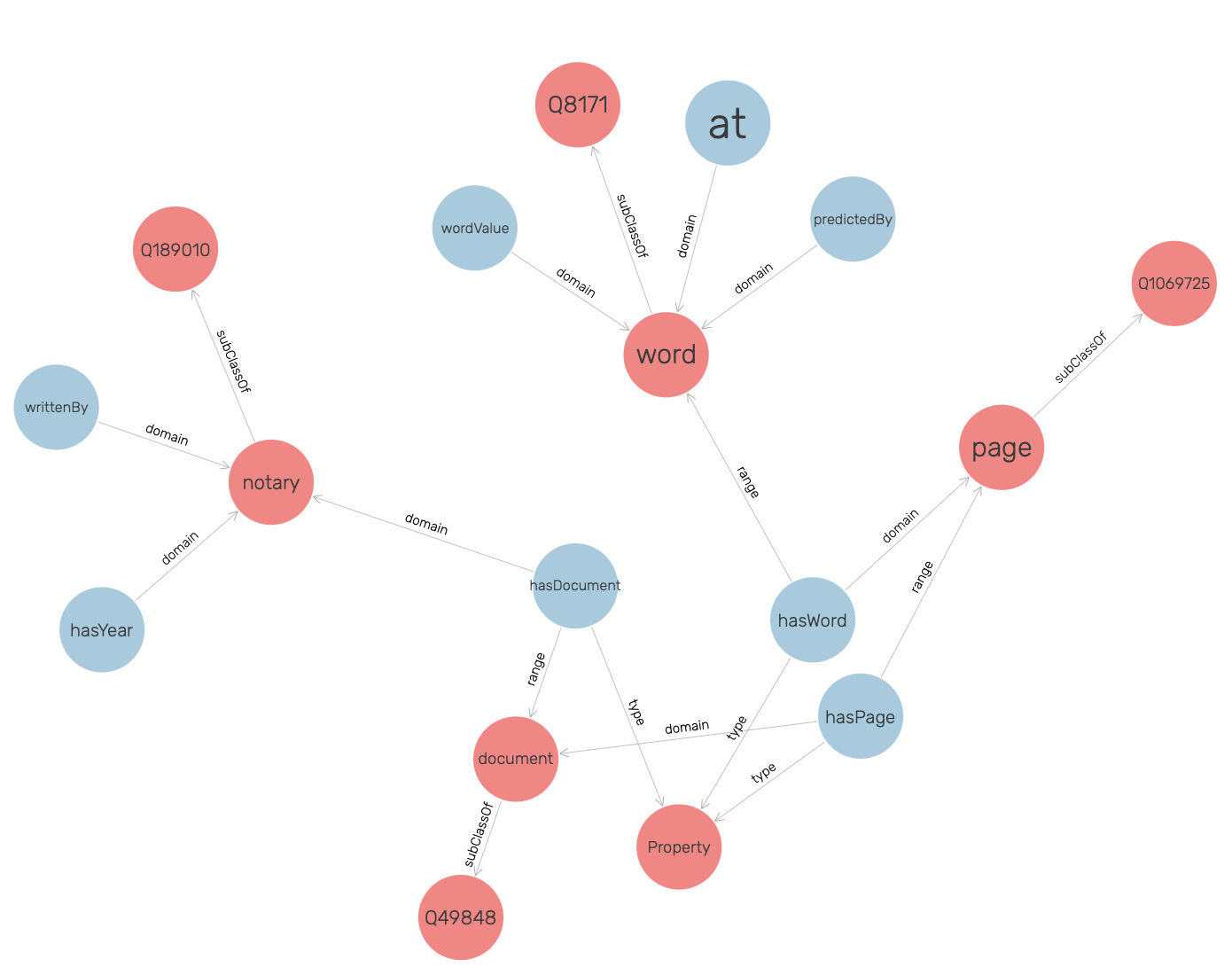
MODELS
Model Training was our next step, Component C. Out of the numerous ML OCR models available, Keras-OCR and YOLO-OCR yielded the most promising results. While experimenting, we tested with YOLOv2, YOLOv3, Calamari, Kraken & Tesseract [1]. The first two models performed unsatisfactorily where those bounding boxes that were detected were unlabeled. Calamari, Kraken & Tesseract were able to detect lines but were unable to detect the words within those lines. This is because they were trained on printed text. Moreover, we wanted to use word detections to build our system [2]. During training, the train to test split was 90 to 10 for both the OCRs.
KERAS-OCR
We trained the recognizer using CRNN (kurupan) on our words dataset. We used the default detector, CRAFT (clovaai_general) as it was able to detect maximum of the words in a given image. Patches from 77 images were used. We observed that although most of the words were detected, the quality of recognition could be improved with further retraining.
YOLO-OCR
The prediction was performed in four steps. Firstly, we passed a test image to the trained YOLO-OCR model to localize all the possible words’ coordinates and write them to a text file. Then, we cropped all the detected words and saved them as .png images. Thirdly, we resized the generated patches to match the input size of the CRNN model. Finally, we passed the .png images to the CRNN model to recognize the word.
The above two images show detection in Keras-OCR vs YOLO-OCR. Although fewer words were detected with respect to Keras-OCR, the quality of recognition was much better in YOLO-OCR.
[1] Alrasheed, N., Prasanna, S., Rowland, R., Rao, P., Grieco, V. and Wasserman, M., October. Evaluation of Deep Learning Techniques for Content Extraction in Spanish Colonial Notary Records. In Proceedings of the 3rd Workshop on Structuring and Understanding of Multimedia heritAge Contents, 23-30 (2021).
[2] Alrasheed, N., Rao, P. and Grieco, V., Character Recognition Of Seventeenth-Century Spanish American Notary Records Using Deep Learning. Digital Humanities Quarterly 15(4) (2021).